Continuous Integration and Continuous Deployment
Overview
Jenkins provides three different project types that can define your continuous project:
Freestyle Projects: Freestyle (“chained”) projects (also called jobs) have been used to define the build flow almost from the day Jenkins was born. They use job orchestration tools such as the Job DSL plugin or Jenkins Job Builder. Freestyle jobs are still supported and are useful in specific situations but are not recommended for most new development.
Freestyle jobs only provide sequential steps although they can be chained with upstream/downstream. They are also not defined in code, only through the GUI and do not provide centralized configuration.Pipeline Projects: Jenkins Pipeline is a tool for defining your Continuous Delivery/deployment flow as code. It is a separate fundamental “type” in Jenkins that conceptualizes and models a Continuous Delivery process in code. Two syntaxes are supported:
- Scripted: sequential execution, using Groovy expressions for flow control
- Declarative: uses a framework to control execution
Both syntaxes use a customized DSL (Domain-Specific Language) that is based on Apache Groovy to programmatically manipulate Jenkins Objects. The Pipeline defines the entire continuous delivery process as code and is not a job creation tool like the Job DSL plugin or Jenkins Job Builder.A Pipeline is defined in a Jenkinsfile that uses a DSL based on Apache Groovy syntax. The deployment flow is expressed as code; it can express complex flows, conditionals and such. The Jenkinsfile is stored in an SCM. Pipeline works with SCM conventions such as Branches and Git Pull Requests and applies versioning, testing and merging against your CD Pipeline definition. Classic Web UI configuration is possible. Pipeline-as-code allows the entire team to collaborate on the continuous delivery process: from development, to QA, all the way through to operations and production.
Limitations of Freestyle projects
Modern continuous delivery and deployment is often much more complex than what chained jobs can support. Even when the objectives can be achieved with Freestyle, the result is cumbersome, hard to maintain, and difficult to visualise. It is not possible — or difficult — Many continuous objectives cannot be solved or, at best, are very difficult to implement with Freestyle:
Requires (complex) conditional logic:
Continuous flows often require some conditional logic to be applied. In many cases, it is not enough to simply chain jobs in a linear fashion. Often, we do not want to simply say run job A, then run job B after Job A is finished, and follow it with job C. In real-world situations, things are more complicated than that. We want to run something (call it A), and, depending on the result, invoke B1 or B2, then run in parallel C1, C2 and C3, and, finally, execute job D only when C jobs are finished successfully.
Requires resource allocation and cleanup:
Resource allocation needs careful thought and is often more complicated than a simple decision to run a job on a predefined agent. There are cases when agent resources must be allocated dynamically; for example, workspace needs to be defined during runtime, or cleanup depends on the result of some action.
Involves human interaction for manual approval:
While continuous deployment process means that the whole flow ends with deployment to production, manual approval may needed at some point. For example, someone may need to confirm a step, or a failed process may need manual input about reasons for the failure and so on. Human interaction — allowing us to pause, inspect and resume the flow — must be supported as part of the project definition.
Should be resumable at some point on failure:
Some deployment flows run for a couple of hours or even days. If the hardware fails along the way, we need a mechanism to restart the deployment flow from a defined place rather than having to rerun it from the beginning.
Advantages of Pipeline over Freestyle
Can be restarted - All Declarative Pipelines can be restarted if necessary. CloudBees CI also supports checkpoints that allow the flow of a Scripted Pipeline to be restarted from defined points.
Advanced visualisation:
The idea, from the start, was to combine the flexibility and maintainability accomplished with DSL and Groovy with advanced visualisation. We define the flow through code and monitor the result through visualisation. Blue Ocean further enhances the visualization that is provided.
SCM friendly:
Pipelines are defined in the plain-text Jenkinsfile so can be stored in the same repository as the application code and can be treated like any other code. We can commit the Jenkinsfile to the repository, use pull requests, code reviews and so on. With the Multibranch Pipeline feature, we can store the script in a Jenkinsfile and define different flows inside each branch.
We discuss Scripted and Declarative Pipeline syntax more below.
To summarize, Pipeline has the following advantages:
- Durable: The Jenkins master can restart and the Pipeline continues to run
- Pausable: can stop and wait for human input or approval
- Versatile: supports complex real-world CD requirements (fork, join, loop, parallelize)
- Extensible: supports custom extensions to its “DSL” (Domain-specific Language)
- Reduces number of jobs
- Easier maintenance
- Decentralization of job configuration
- Easier specification through code
Jenkins vocabulary
- Controller: (previously called “master” is a computer, VM or container where Jenkins is installed and run. It serves requests and handles build tasks.
- Agent: (previously called “slave”) is a computer, VM or container that connects to a Jenkins Master. It executes tasks when directed by the Master and has a number and scope of operations to perform.
- Node is sometimes used to refer to the computer, VM or container used for the controller or agent; be careful because “Node” has another meaning for Pipeline.
- Executor: is a computational resource for running builds. It performs operations and can run on any controller or agent, although running builds on masters is strongly discouraged because it can degrade performance and opens up serious security vulnerabilities. An executor can be parallelized on a specific controller or agent.
Jenkins Pipeline sections
The Jenkinsfile that defines a pipeline uses a DSL based on Apache Groovy syntax. The basic structure of a Declarative Pipeline is simple and straightforward:
It is structured in sections, called Stages, each of which defines a chunk of work to be done. The stages are executed sequentially. Typically, a stage corresponds to one of the parts of the Continuous Delivery process such as build, unit test, regression test, or deploy. You can give a stage any name that is meaningful for your application.
Each Stage includes Steps that execute the actual programs and scripts to be run.
- Some Steps are built into Pipeline and many others are provided in plugins.
An Agent statement defines the node where the programs and scripts execute. You can define one Agent to run the entire pipeline or you can specify different agents for different stages.
- The agent section must be coded differently for Agents that run on Kubernetes
Any non-setup work should occur within a stage block. The Pipeline code itself executes on the Jenkins Master node. Most of the code inside stage blocks executes on agent nodes.
We will say much more about these components later and, of course, a real-world Pipeline gets much more complex.
Declarative Vs Scripted Pipeline
Declarative and Scripted Pipelines use different syntaxes, but both are defined in a Jenkinsfile under source code management (SCM) and both use the same pipeline subsystem.
Scripted pipeline: Scripted pipeline was the original syntax. It uses the Pipeline DSL, which is based on Apache Groovy, to define build steps and accomplish in a single script flow what would require many freestyle jobs chained together.
The Pipeline DSL provides a simple way to define common tasks like accessing a SCM repository, defining the node on which a task should run, parallel execution and so on. More complicated tasks can be defined using Groovy, so the pipeline can use conditionals, loops, variables and so on. Groovy is an integral part of Jenkins, so we can also use it to access almost any existing Jenkins plugin or even to operate on Jenkins core features.
To summarize scripted pipeline:- Executed serially, from top down
- Relies on Groovy expressions for flow control
- Requires extensive knowledge of Groovy syntax
- Very flexible and extensible
- Limitations are mostly Groovy limitations
Scripted pipeline works well for power users with complex requirements but novice users can easily mess up the whole system and most users do not need all the flexibility it accords.
Declarative pipeline: The declarative pipeline syntax provides a defined set of capabilities that lets you define a pipeline without learning Groovy. It offers an stricter, pre-defined structure with the following advantages:
- Execution can always be resumed after an interruption, no matter what caused the interruption
- Requires only limited knowledge of Groovy syntax
- Using Blue Ocean simplifies the Pipeline creation process even more
- Encourages a declarative programming model
- Reduces the risk of syntax errors
- Use the script step to include bits of scripted code within a Declarative Pipeline only when you have needs that are beyond the capabilities of Declarative syntax
This is illustrated in the following simple declarative Jenkinsfile:
pipeline { agent { label 'linux' } stages { stage('MyBuild') { steps { sh './jenkins/build.sh' } } stage('MySmalltest') { steps { sh './jenkins/smalltest.sh' } } } }
Tools for working with pipeline
Pipelines can be developed and maintained using different tools:
- Graphical Blue Ocean Visual Editor with the embedded Code Editor
- Jenkins dashboard with the inline editor that is provided
- Jenkins dashboard with a text editor and standard SCM tools
All tools result in the same Jenkinsfile that defines the Pipeline as code so the the tools can be used interchangeably on the same Pipeline.
Classic Web UI Both scripted and declarative pipelines can be created and modified using the web UI. You code the Jenkinsfile using the text editor of your choice then use the Jenkins dashboard to run and configure the Pipeline . Tools are provided to simplify the process: espeically the Declarative Directive Generator for declarative pipelines and the Snippet Generator for scripted pipelines. Each of these can generate a line of code based on the task that is required and information you input to an appropriate form. All features for declarative and scripted pipelines can be implemented this way.
Blue Ocean Graphical Editor The Blue Ocean Graphical Editor greatly simplifies the tasks of creating and running declarative pipelines. It is a visual editor you can use to easily create, modify, and run multibranch declarative pipelines. It provides a visual editor that makes it very easy for novices to create a new pipeline, Add/remove configuration, stages and steps. It includes a Code Editor that can be used to implement pipeline features not supported by the GUI or to do edits that are easier to do with an editor.
- Round-trip to the Jenkinsfile file that is the Pipeline
- Supports Git, GitHub, GitHub Enterprise and Bitbucket Server and Cloud
- Supports most features that the Classic Web UI supports
- Provides visualization and analysis for the Pipeline run
- Generates a Jenkinsfile and stores it in the source code repository
Blue Ocean editor limitations
- The Blue Ocean Visual Editor does not support all pipeline capabilities.
- Use the Blue Ocean Code Editor or another text editor to incorporate such features into your Pipeline.
- The Declarative Directive Generator can help with the syntax when using the Code Editor or a text editor.
- Blue Ocean can run a Pipeline that includes these features.
- Specify environment variables within a block
- post section that defines actions that run at the end of a Pipeline run or an individual stage
- Apply options to the Pipeline
- Use the when directive
- Define and access credentials
Artifacts and fingerprints
An artifact is a file produced as a result of a Jenkins build. The name comes from Maven naming conventions. A single Jenkins build can produce many artifacts By default, they are stored on the Jenkins master that ran the Pipeline that created them, not on the agent where the step ran. If they are not archived, they are deleted when the Pipeline completes and the workspace is wiped. Archiving keeps those files in ${JENKINS_HOME} unless you delete them.
A fingerprint is the MD5 checksum of an artifact. Each archived artifact can be fingerprinted; merely check the “Fingerprint” box when you create the archiving step in the Blue Ocean Visual Editor. Jenkins uses fingerprints to keep track of artifacts without any ambiguity.
Most archives should be fingerprinted; the details of how one tracks archives using fingerprints is outside the scope of this cheatsheet except to say that a database of all fingerprints is managed on the master in the ${JENKINS_HOME}/fingerprints directory.
Later, we will look at ways to give an archive a name that is unique.
Archiving artifacts
Projects can be configured to archive artifacts based on filename patterns; archived artifacts are available for testing and debugging after the pipeline run finishes. Archived artifacts are kept forever unless a retention policy is applied to builds to delete them periodically
Patterns for archiving artifacts
Your Pipeline uses patterns to control which artifacts are archived. For example:
- my-app.zip: The file my-app.zip, at the workspace’s root
- images/*.png: All files with the .png extension in the images folder under the workspace’s root
- target/**/*.jar: All files with the .jar extension, recursively under the target folder, under the workspace’s root
Archives — Internal details
Blue Ocean enables you to archive artifacts easily but you may eventually need to understand some of the nitty-gritty details.
Artifacts can be archived in the post section of the Pipeline or at the end of the stage that generated the artifact. Jenkins tracks these artifacts forever, across builds, jobs, nodes and folders. Once archived, an archive is attached to the build that produced it.
Artifacts are stored at:
http://${JENKINS_URL}/job/${YOUR_JOB}/${BUILD_NUMBER}/artifact
In a production environment, your build chain system (Maven, Gradle, Make, etc.) should publish artifacts to an artifact repository such as Artifactory, Nexus, etc. Teams can also deploy artifacts from Jenkins to test environments. Use the Copy Artifact Plugin to take artifacts from one project (Pipeline run) and copy them to another Project
Accessing archived artifacts
In Blue Ocean, use the “Artifact” screen for a build to view the artifacts created:
Each Pipeline generates a pipeline.log artifact when it runs. Additional artifacts are listed here if the Pipeline is coded to create them. In our example, the artifact is in the target directory and is called my-app-1.0-SNAPSHOT.jar
Artifacts are also visible on the main Build page in the Classic Jenkins Web UI:
Artifact retention policy
The artifact retention policy is coupled with the build retention policy: deleting a build deletes all attached artifacts.
Important builds can be kept forever but most builds should be deleted regularly. The Jenkins instance can be configured to do this automatically, based on either the age of the build (how many days to keep a build) or number (maxiumum nunber of builds to keep).
Further Read
To learn more about artifacts, read the following:
- A Very Quick Guide to Deploying Artifacts with Jenkins
- Documentation for the Copy Artifact plugin
- CloudBees Support, Best Strategy for Disk Space Management: Clean Up Old Builds
JUnit Support
JUnit is a common testing framework for Java programs. The Jenkins JUnit plugin provides steps that implement JUnit as a publisher which consumes XML test reports and generates some graphical visualization of the historical test results. Junit provides a web UI for viewing test reports, tracking failures and so forth. It is useful for tracking test result trends and works with all supported build tools. You must specify the appropriate path name for the XML test reports generated by the build tool you are using
In this course, JUnit means the Jenkins publisher that is implemented with the JUnit plugin.
JUnit is very useful for monitoring your test results. Using the JUnit output is a subject for QA and operations people so we do not discuss it in this class, but we can add it to our Pipeline. Because the Pipeline is glue, JUnit works with the XML test reports generated by any build tools.
For more details, see the junit step reference.
Environment variables
Environment variables are set as directives that define key-value pairs and can be used in a Pipeline They come from various sources:
- Jenkins recognizes some environment variables that are set in the shell.
- Jenkins sets its own specific environment variables, such as BUILD_NUMBER, NODE_NAME and JOB_NAME.
- Many plugins define environment variables.
You can see the list of environment variables recognized on your Jenkins instance by following the Manage Jenkins → System information link on the Jenkins dashboard; we will discuss this more later.
Jenkins Set Environment Variables lists all environment variables that Jenkins can set. We will discuss using these environment variables in more detail later.
Parallel stages
Stages can be run in parallel, which can reduce the execution time for the Pipeline.. This is especially useful for long-running stages and builds for different target architectures or operating systems (Debian/Fedora, Android/iOS) or different software versions (JVM8/11), et cetera. Builds and tests of independent modules can be run in parallel.
Each “parallelized branch” is a stage. A stage can use either steps or parallel at the top level; it cannot use both. Other implementation details for parallel stages are:
- A stage within a parallel stage can contain agent and steps sections.
- A parallel stage cannot contain agent or tools because they are not relevant without steps.
- By default, if one parallel stage fails, the other stages continue to execute. Add failfast true to force all parallel processes to abort if one stage fails.
Pipeline run details for parallel
Blue Ocean graphically depicts that the stages are running in parallel: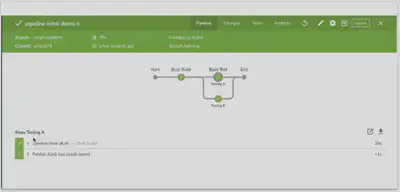
Blue Ocean separates output for steps; this also works across parallel stages. Blue Ocean separates the output for each step in each parallel stage.
Scheduling
By default, Jenkins tries to allocate a stage to the last node on which it (or a similar stage) executed. This may mean that multiple parallel steps execute on the same node while other nodes in the cluster are idle.
Pipeline parallel is NOT, by default, a load balancer. The default scheduling is based on:
- SCM updates are more efficient than SCM checkouts
- Some build tools (such as Maven and RVM) use local caches, and they work faster if Jenkins keeps building a job on the same node.
The disadvantage is that some nodes may be left idle while other nodes are overloaded. Use the Least Load Plugin to replace the default load balancer with one that schedules a new stage to nodes with the least load.
Limits to parallelization
Jenkins does not impose a limit on the number of parallel stages used in a single stage. Using a small number of parallel stages improves the speed of a pipeline but, because each parallel branch uses resources to set up and wait, a very large number of parallel stages may actually degrade the pipeline performance, even if the only statement in each stage is an echo statement.
A large number of parallel stages that attempt to pull from a common resource, such as an artifact repository, may also cause performance issues.
Some internal architectural issues between Groovy, the Groovy CPS library, and the JVM classfile format occasionally cause even medium-sized pipelines to fail during compilation with errors such as “Method code too large” or “Class too large”.
In summary, using a few parallel stages can improve the performance of your Pipeline but you should avoid using too many parallel stages.