What is Docker - Big 📸
Overview
We use the command line to create a new container. The client takes the command and makes the appropriate API request to the containers/create endpoint here in the engine. Hey, create me a container, yeah. And the engine here pulls together all of the required kernel stuff, and out pops a container. It is a beautiful thing, but this is all big picture stuff.
Kernel Internals
We use two main building blocks when we’re building containers: namespaces and control groups. Both of them are Linux kernel primitives. And now we’ve got equivalents on Windows. Hooray!
Namespaces
Namespaces are about isolation. Let us take an operating system and carve it into multiple isolated virtual operating systems. It’s a bit like hypervisors and virtual machines. So in the hypervisor world, we take a single physical machine with all of its resources, like CPU and RAM, and we carve out one or more virtual machines, and each one gets a down slice of virtual CPU, virtual memory, virtual networking, virtual storage, the whole shebang. Well, in the container world, we use namespaces to take a single operating system with all of its resources, which tend to be higher‑level constructs like file systems and process trees and users, and we carve all of that up into multiple virtual operating systems called containers. Well, each container gets its own virtual or containerized root file system, its own process tree, its own Eth0 interface, its own root user, the full monty.
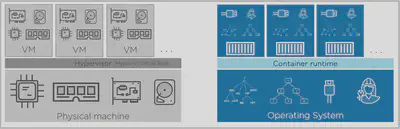
And just the way a virtual server in the hypervisor world looks, tastes, and smells like a regular physical server, in the container world, each container looks, smells, and feels exactly like a regular OS. Only it’s not. All three of these here are sharing a single kernel on the host.
But everything’s isolated so that the stuff inside of one container doesn’t even know about these others over here. It’s ignorant.
the concept’s the same for Linux and Windows. Slice and dice the OS and provide isolation. So that’s namespaces, and it’s great and all.
Control groups
Control groups are about grouping objects and setting limits. Like any multi‑tenant system, there’s always the fear of noisy neighbors. I mean, the last thing that container A wants here is D over here throwing all‑night parties and chewing through all the CPU and RAM. So to realistically have containers, you know, something that you’d run in production, we need something to police the consumption of system resources. In the Linux world, this is control groups. And if you’re cool, you call them cgroups. In Windows, it’s job objects. But credit to the Microsoft folks. They seem to be playing nice and generally calling them control groups as well. After all, they do a similar thing, and who wants multiple names for everything. But call them what you want. The idea is to group processes and impose limits. Now I’m sure you’ve already got it. But control groups let us say, okay, container A over here is only going to get this amount of CPU, this amount of memory, and this amount of disk IO and then container B this amount and these as well. And with these two technologies, namespaces and control groups, we have got a realistic shot at workable containers.
Union File System
Oh, and a union file system or some way of combining a bunch of read‑only file systems or block devices, lashing a writeable layer on top, and presenting them to the system is a unified view.
Take these three, and we have got modern containers. And that’s exactly what Docker did. It came along, and it made all of this easy. And the rest is history.
Docker Engine
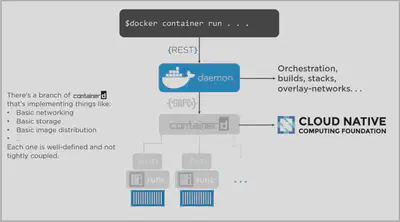
We have got the Docker client where we slap in commands like docker container run. We’ve got the daemon implementing the REST API. Containerd here is the container supervisor that handles execution of the lifecycle operations, things like start, stop, pause, and unpause. And we’ve got the OCI layer that does the interfacing with the kernel. All right, on Linux, it works like this. The client asks the daemon for a new container. The daemon gets containerd to start and manage containers, and runc at the OCI layer actually builds them. Runc, by the way, is the reference implementation of the OCI runtime spec, and it’s the default runtime for a vanilla installation of Docker. Now Docker on Linux has looked like this since 1. 11 way back in April 2016. But that’s just Linux. Things are a bit different on Windows. We still got the client and the daemon here at the top. But instead of containerd in the OCI layer, we’ve got something called the compute services layer. Now, okay, I suppose that does make it architecturally a bit different, but the user experience is the same. This kind of plumbing stuff here at these kind of layers, it’s interesting, but it’s all super low level. Day to day, we’re not affected. I mean, the API up here on Windows is exactly the same, so no stress. Now we’ll want to throw Microsoft a bone here. They’re not doing anything nefarious or trying to be different. In fact, they’re doing a cracking job in the community. It was just a timing thing. So at the same time that Docker was doing all of this refactoring into containerd and runc, Microsoft was also getting ready to ship Server 2016. Now in order for them to hit their ship dates, they just couldn’t wait for containerd and the OCI stuff to bake. So we ended up with some low‑level differences. Now I’ll give my opinion here, which I probably shouldn’t. But I don’t think it will be long before we’re seeing containerd in an OCI runtime here on Windows. But that’s just my opinion. I don’t speak for Microsoft or anybody else, for that matter. Anyway, this is the engine today. Now let me run through the creation of a new container on Linux. Generally speaking, we use the Docker client to create containers. The command is docker container run, and we give it a bunch of parameters. Okay, well the client takes that command and it posts it as an API request to the containers/create endpoint in the daemon. But guess what? All this engine refactoring has left the daemon without any code to execute and run containers. Seriously, Docker no longer even knows how to create containers. All that logic’s ripped out and implemented in containerd in the OCI. So to create the container, the daemon calls out to containerd over a gRPC API on a local Unix socket. And even though containerd has got container in its name, even it can’t actually create a container. What? Yeah, that’s right. All the logic to interface with the namespaces and stuff in the kernel is implemented by the OCI. So for Docker on Linux, that defaults to runc, though you can switch that out for pretty much any OCI‑compliant runtime. All right, well, things work like this. Your init process starts the daemon. The daemon starts containerd, which is a daemon process, so a long‑running process, and this is kind of the glue between the daemon here and runc below. Anyway, containerd starts a shim process for every container, and runc creates the container and then exits. So runc gets called for every new container, but it doesn’t stick around. The shim does though, and it’s the same for more. So see here how containerd effectively manages multiple runcs or shims, and that’s pretty much the process. And you know what? Architecturally, it’s great. I mean, it’s modular and composable and reusable, all the buzzwords that we love. In fact, actually, in case that’s all jargon to you, all we’re saying with composable and reusable is that containerd and runc here are potentially swappable. Definitely runc. You can swap that out for pretty much any OCI‑compliant runtime. And they’re both reusable as well, so both easily reused by players in the ecosystem. And like I was saying, it’s all good. But you know what? All of this decoupling of the container here from the daemon and even containerd, it lets us do really cool stuff like restart the daemon in containerd and not affect running containers. And if you do Docker in production, oh my goodness, you will know what a huge deal this is. I mean, Docker’s cranking out new versions of the engine like nobody’s business. And upgrading them in the past, like when an upgrade would kill all of your running containers, let’s just say it was a challenge. But now, we can restart these here, leave all of our containers running, and when they come back up, they just rediscover running containers and reconnect to the shim. It’s a beautiful thing. Okay, so a few last things The daemon here still implements a bunch of stuff, but these days it’s mostly higher‑level value‑add stuff. That core plumbing stuff is mostly broken out into containerd in the OCI layer. In fact, more is being broken out to containerd even as I record. It’s things like Swarm orchestration, overlay networking, builds and stacks, cool stuff like that that’s getting implemented in the daemon. Oh, yeah. Containerd is a Cloud Native Computing Foundation project. In fact, so is gRPC. And they’re a great fit together, actually. In fact, keep your eye on gRPC. It is the future. What else did I want to say? Oh, yeah. So it’s a one‑to‑one relationship here between containers and runc or the shim. For every container that you create, a new runc process fork it and then exits, leaving every container with its own shim process, connecting it back to containerd. Okay, so it’s clearly a one‑to‑many relationship between containerd and shims. So you only ever have one containerd process running on a system, and it’s a daemon process, long lived. But runc isn’t. That just starts a container and then bows out. Now there’s also a lightweight CLI for containerd, but it’s not for general consumption. In fact, the whole point of containerd and runc are that they’re driven by higher‑level tools. And you know what? I could probably talk all day about this stuff, and you’re probably nodding off if you haven’t already. So with that in mind, I know this has been long, but it’s kind of been a Linux fest. So I’m going to do a quick 5 minutes on Windows, and then we’ll do the recap.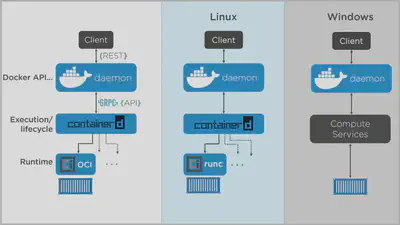
Now let me run through the creation of a new container on Linux. Generally speaking, we use the Docker client to create containers. The command is docker container run, and we give it a bunch of parameters. Okay, well the client takes that command and it posts it as an API request to the containers/create endpoint in the daemon. But guess what? All this engine refactoring has left the daemon without any code to execute and run containers. Seriously, Docker no longer even knows how to create containers. All that logic’s ripped out and implemented in containerd in the OCI. So to create the container, the daemon calls out to containerd over a gRPC API on a local Unix socket. And even though containerd has got container in its name, even it can’t actually create a container. What? Yeah, that’s right. All the logic to interface with the namespaces and stuff in the kernel is implemented by the OCI. So for Docker on Linux, that defaults to runc, though you can switch that out for pretty much any OCI‑compliant runtime. All right, well, things work like this. Your init process starts the daemon. The daemon starts containerd, which is a daemon process, so a long‑running process, and this is kind of the glue between the daemon here and runc below. Anyway, containerd starts a shim process for every container, and runc creates the container and then exits. So runc gets called for every new container, but it doesn’t stick around. The shim does though, and it’s the same for more. So see here how containerd effectively manages multiple runcs or shims, and that’s pretty much the process. And you know what? Architecturally, it’s great. I mean, it’s modular and composable and reusable, all the buzzwords that we love. In fact, actually, in case that’s all jargon to you, all we’re saying with composable and reusable is that containerd and runc here are potentially swappable. Definitely runc. You can swap that out for pretty much any OCI‑compliant runtime. And they’re both reusable as well, so both easily reused by players in the ecosystem. And like I was saying, it’s all good. But you know what? All of this decoupling of the container here from the daemon and even containerd, it lets us do really cool stuff like restart the daemon in containerd and not affect running containers. And if you do Docker in production, oh my goodness, you will know what a huge deal this is. I mean, Docker’s cranking out new versions of the engine like nobody’s business. And upgrading them in the past, like when an upgrade would kill all of your running containers, let’s just say it was a challenge. But now, we can restart these here, leave all of our containers running, and when they come back up, they just rediscover running containers and reconnect to the shim. It’s a beautiful thing.
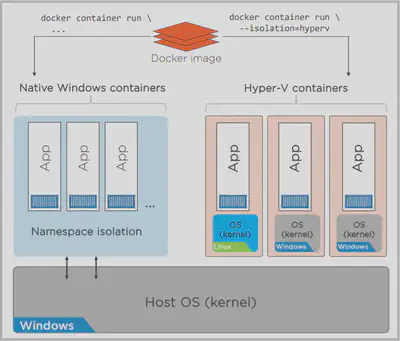
Now then, Hyper‑V containers. Okay, yes, it’s true, we’ve actually got two different types of Windows container, native Windows containers and Hyper‑V containers, and both are for the native Win32 apps, though you can do Linux inside of a Hyper‑V container. But why two options? Well, native containers use namespaces for isolation, and down at the bottom, they all share the host’s kernel, but sometimes that’s not what you need. I mean, from a security perspective, maybe you don’t think namespace isolation is all it’s cracked up to be, or maybe you’ve got an app that needs a slightly different kernel, or a different patch set, or whatever, enter Hyper‑V containers. When you spin up a Hyper‑V container, Windows actually spins up a lightweight Hyper‑V VM in the background. Now, it is lightweight, so it’s got less of a performance overhead than a full‑blown VM. But inside, you still get a full‑blown OS, so it’s not using the host’s kernel, a separate isolated kernel, and then you run your container on that. So, looking at the diagram, on the left side, we’ve got the host OS at the bottom. Well, look, it’s at the bottom for the lot, really. But on the left side, the native containers are actually using it. They spin up directly on the host, leverage its kernel, and isolation is done with namespaces. On the right, we’ve got a VM. It’s lightweight and all that jazz, remember, but inside, it’s still running a totally isolated kernel, and it can be Windows or Linux inside, both work with Hyper‑V isolation. Anyway, the container runs on that, and obviously, we can have a load of these on each host, but it’s always one container per VM. That’s kind of the point. Cool and all, but doesn’t that make life a bit complicated? Well, not really. You just developing containerized Windows app the same way that you always have. There’s only one type of build, and then whether or not you go with native containers or Hyper‑V is just a deployment decision. If you want Hyper‑V, you give the docker run command, then ‑‑isolation=hyperv switch, and to run it natively, you leave that switch off, and that’s it.