Work with Real-Time Streaming Data
Overview
Amazon Kinesis makes it easy to collect, process, and analyze real-time, streaming data so you can get timely insights and react quickly to new information.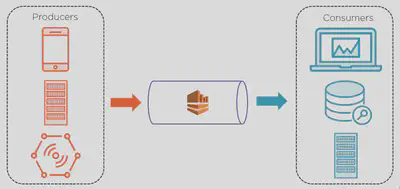
Why Kinesis
What was before the stream processing? We had batch processing!
We had the number of producers which were generating data and they were aggregating this data and storing it in some distributed storage like S3/HDFS. And we had consumers who would read and process this data.
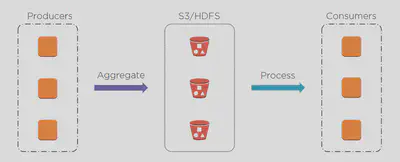
The biggest problem with this approach was it had very high latency. It could take hours from when the data was generated till the time it could be consumed. It could work for some use cases but would not work for many. Specially when the need is to analyze data real time like stock prices, clickstream analysis, fraud detection etc.
The other disadvantage was the architecture was tightly coupled and hard to maintain. Let’s take an example of a retail website:
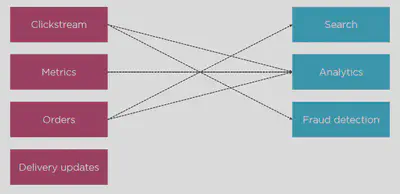
The disadvantages of this architecure:
- Need to implement each point-to-point connection
- Each one is complex to implement and should be maintained
- Up to N^2 connections to maintain
- Adding a new data source might need rewiring
- A mess!
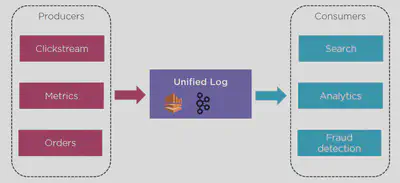
In the new architecture we have something called a Unified Log (Kinesis/Apache Kafka) where the consumers read from the Unified Log only.
Kinesis Components
The Kinesis family includes Kinesis Data Streams, Kinesis Data Firehose, Kinesis Data Analytics and Kinesis Video Streams.
Kinesis Data Streams
In the very core of Kinesis is an immutable log. It’s a log of ordered immutable records and every record has a sequence number. You can only append new data to the log.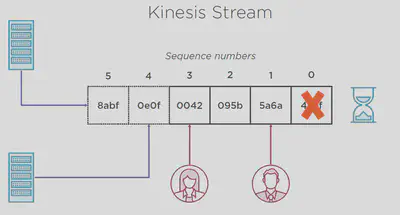
All the readers see the items in the same order and kinesis does not store the position of the readers. The reader is responsible for keeping record of which items they have processed.
When a record is read from the log it’s not removed.
A record could be read multiple times by the same consumer or different consumers as may the need be.
Records are retained in the log for 24 hours and deleted automatically by default (but can be configured to retain for up to 7 days) and this is the only way a record could be removed.
Logs are stored in a shard. Shard is the unit of scaling and you could have multiple shards and each shard has it’s own log.
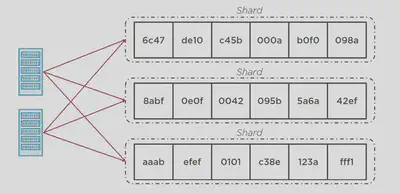
Data is processed in “shards” – with each shard able to ingest 1000 records per second.
There is a default limit of 500 shards, but you can request an increase to unlimited shards.
A record consists of a partition key, stream name and data blob (up to 1 MB).
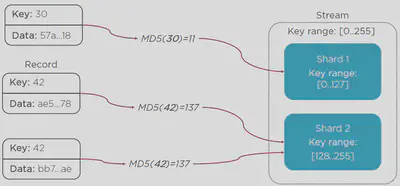
The partition key could be a random number or could be deduced from the data blob.
When you write data to a shard it’s 3 way replicated to different AZs.
One shard provides a capacity of 1000 write records per second upto a max of 1 MB/sec.
One shard provides a capacity of 5 read records per second upto a max of 2MB/sec
The total capacity of the stream is the sum of the capacities of its shards.
Kinesis Data Streams supports resharding, which lets you adjust the number of shards in your stream to adapt to changes in the rate of data flow through the stream. There are two types of resharding operations: shard split and shard merge.
- In a shard split, you divide a single shard into two shards.
- In a shard merge, you combine two shards into a single shard.
Splitting increases the cost of your stream (you pay per-shard).
Merging reduces the number of shards in your stream and therefore decreases the data capacity—and cost—of the stream.
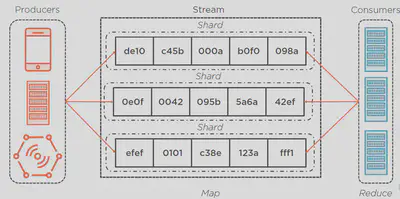
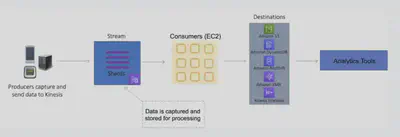
The following diagram shows producers placing records in a stream and then consumers processing records from the stream. There are multiple options for destinations.
Kinesis API
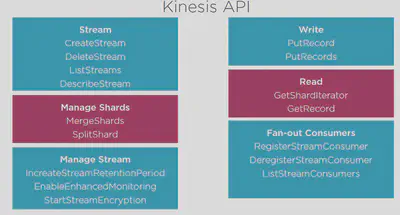
More details here: Kinesis-CLI
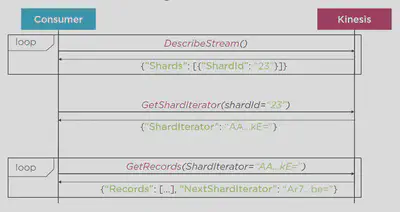
Reading data from Kinesis stream
Scaling shards
