Managed NoSQL Database
Overview
DynamoDB is Amazon’s NoSQL solution promising “performance at any scale”. It can be used as a key-value store or as a document store for billions of datasets if need be.
DynamoDB is serverless, fully managed NoSQL (non-relational) database service designed for Online Transactional Processing (OLTP) workloads.
- Flexible Schema
- JSON document or key-value data structures
- Supports event-driven programming
- Accessible via AWS Management Console, CLI, and SDK
- Availability, durability, and scalability built-in
- Scales horizontally
- Provides fine-grained access control
- Integrates with other AWS services
Tables and Partitions
In Amazon DynamoDB, data is stored in tables. A table contains items with attributes. You can think of items as rows or tuples in a relational database and attributes as columns.
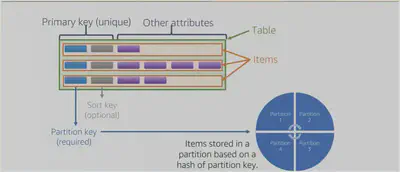
DynamoDB stores data in partitions and divides the tables items into multiple partitions based on the Partition Key value.
A partition is an allocation of storage for a table, backed by SSDs and automatically replicated across multiple AZs within a Region.
Partition Management is handled by DynamoDB. The Partition Key of an item is also known as hash attribute.
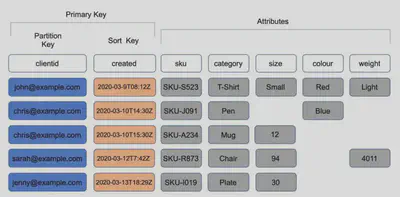
A table has a primary key that uniquely identifies each item in the table. There are two types of primary keys:
- Partition Key − This simple primary key consists of a single attribute referred to as the “partition key.” Internally, DynamoDB uses the key value as input for a hash function to determine storage.

- Partition Key and Sort Key − This key, known as the “Composite Primary Key”, consists of two attributes, the partition key and sort key. DynamoDB applies the first attribute to a hash function, and stores items with the same partition key together; with their order determined by the sort key. Items can share partition keys, but not sort keys. DynamoDB builds an unordered index on the partition key attribute and a sorted index on the sort key attribute.
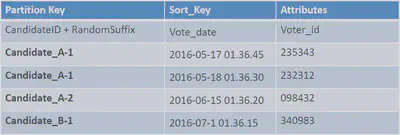
DynamoDB Write Sharding
- Imagine we have a voting application with two candidates, candidate A and candidate B.
- If we use a partition key of candidate_id, we will run into partitions issues, as we only have two partitions
- Solution: add a suffix (usually random suffix, sometimes calculated suffix)
Durability and Availability
Your data is highly durable and available in a DynamoDB table. All data is automatically replicated across several independent solid-state disks in separate servers in fault-isolated data centers. Any write call you create will not return successfully until the data is redundantly stored (at least two copies). Other copies will very rapidly converge (usually a second or less). If any of the servers housing your data should suffer a failure, they are removed from the replication set in seconds and automatically replaced. This allows DynamoDB to deliver against a Service Level Agreement of four nines (that’s 99.99%) of availability.
Consistency
Consistency is the ability to read data with the understanding that all prior writes will be reflected in the results returned. Reads can be “strongly” consistent or “eventually” consistent.
Eventual Consistent
- Consistency across all the copies of the data across the AZs is usually reached within a second. Repeating a read after a short interval after being written or changed should return the updated data within a second.

Strongly Consistent
- The Strongly consistent read returns a result that reflects all writes that received a successful response prior to the read.

DynamoDB Access Control
- Authentication and Access control to DynamoDB is all managed by IAM.
- You can create an IAM user within your account who has specific permissions to access and create DynamoDB tables.
- You can also create an IAM role which enables you to obtain temporary access keys that can then be used by other AWS services like EC2/Lambda to access DynamoDB.
- VPC Endpoints available to access DynamoDB without internet inside a VPC
- Encryption at rest using KMS
- Encryption in transit using SSL / TLS
- You can also use a special IAM condition to restrict user access to only their own records. This can be done by adding a condition to an IAM policy and this will allow the user to access only items where the partition key value matches their user ID. Below is an example:
{
"Version" : "2012-10-17",
"Statement" : [
{
"Sid": "AllowAccessToOnlyItemsMatchingUserID",
"Effect": "Allow",
"Action": [
"dynamodb:GetItem",
"dynamodb:BatchGetItem",
"dynamodb:Query",
"dynamodb:Scan"
],
"Resource": [
"STUDENTTABLEARN"
],
"Condition" : {
"ForAllValues:StringEquals" : {
"dynamodb:LeadingKeys" : [
"STUDENTID"
]
}
}
},
{
"Sid": "ReadAllCourses",
"Effect": "Allow",
"Action": [
"dynamodb:GetItem",
"dynamodb:BatchGetItem",
"dynamodb:Query",
"dynamodb:Scan"
],
"Resource": [
"COURSESTABLEARN"
]
}
]
}
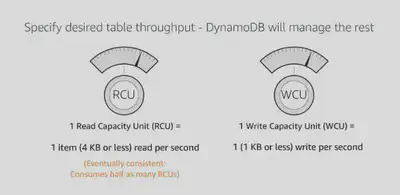
Provisioned Throughput
You must specify read and write throughput values when you create a table. DynamoDB reserves the necessary resources to handle your throughput requirements and divides the throughput evenly among partitions.
Throughput is specified in terms of:
- read capacity units (RCU) - the number of strongly consistent reads per second of items up to 4 KB in size
- write capacity units (WCU) - the number of 1 KB writes per second
- Note that updating a single attribute in an item requires writing the entire item.
- Your throughput is generally evenly divided among your partitions – so it is important to design for requests which are evenly distributed across your keys.
- Be aware that a single item can never be read at more than 3000 RCU, or written at more than 1000 WCU (or a linear combination of the two).
- Eventually Consistent reads are levied at half the cost of Strongly Consistent reads – two 4KB EC reads will only consume 1 RCU.
- What happens if you try to use more throughput than you have provisioned? DynamoDB throttles your request.
- ProvisionedThroughputExceededException is one that you might see on your dynamo db table if your request rate is too high for the read and write capacity provisioned on the DynamoDB table.
- If you are using the AWS SDK it’s going to automatically retry the requests until they are successful.
- If you’re not using the SDK you’re going to have to configure your application to do one or
both of the following things:
- Reduce the request frequency
- Implement exponential back off.
DynamoDB Auto Scaling
Many tables have seasonality in their loads – perhaps even with a regular ebb and flow of traffic through a business day. Auto Scaling is enabled by default, and using it everywhere is highly recommended. RCU and WCU are managed separately, and you set a minimum, a maximum, and a target utilization (in percent) for each.
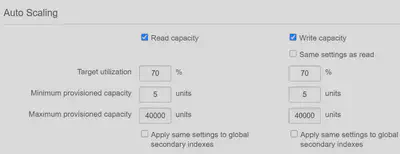
On-Demand Capacity
- With On-Demand capacity charges will apply for reading writing and storing your data
- You don’t need to specify your capacity requirements
- DynamoDB will instantly scale up and down based on the activity of your application.
- Great for unpredictable workloads.
- Also it’s also really good for serverless applications where you want to pay for what you use when you use it.
Basic Item Requests
Write
- PutItem – Write item to specified primary key.
- UpdateItem – Change attributes for item with specified primary key. But it basically overwrites the entire item so you’ll be metered for all the WCUs required.
- BatchWriteItem – Write bunch of items to the specified primary keys.
- DeleteItem – Remove item associated with specified primary key - it costs the same number of WCUs to delete the item as it would to create it.
Read
GetItem – Retrieve item associated with specified primary key.
BatchGetItem – Retrieve items with this bunch of specified primary keys.
Query – For specified partition key, retrieve items matching sort key expression (forward/reverse order).
- By default a query returns all the attributes for the items. But you can use the projection expression parameter if you want the query to only return specific attributes that you’re looking for.
- Results are always sorted by the sort key if they’re numeric or ASCII by default in ascending order.
- You can reverse the order by setting the ScanIndexForward parameter to false.
- Query is not just powerful, it is efficient. Rather than charging RCUs based on individual item sizes (rounding to 4KB increments), it sums the size of all the items in the result set and then rounds to the nearest 4KB.
Scan – Give me every item in my table.
- It’s not something you should be doing often, and when you do, it is recommended that you control the rate to avoid consuming all the provisioned throughput for your table.
- By default similar to query, a scan returns all the attributes for the items. But you can use the projection expression parameter if you want to only return specific attributes that you’re looking for.
- And you can also filter the results of the scan once it’s been run.
Checkout CLI references here: DynamoDB-CLI
Secondary Indexes
To perform queries on attributes that are not part of the table’s primary key, create a secondary index.
There are two types: local and global.
NonKeyAttributes can be copied (projected) from the table into an index. These are in addition to the primary key attributes and index key attributes, which are automatically projected.
You can define up to 5 global secondary indexes and 5 local secondary indexes per table.
Let’s take an example of a table containing actors and actresses and the various movies in which they’ve appeared. You might have an access pattern where you want to fetch all movies for a particular actor in a way where you can filter based on the name of the movie. In this table, the actor’s name is the partition key and the movie name is the sort key. Your base table would look as follows:
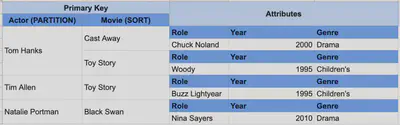
Then, you might have a second access pattern that wants to find all movies for an actor within a given time range. You could set up a local secondary index where the partition key is Actor and the sort key is Year.
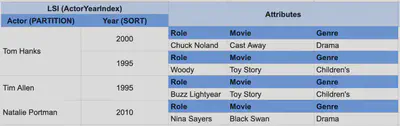
Note: This is the same data, it has just been rearranged due to a secondary indexes. In this example, the partition key is the same for our base table and index – the actor’s name.
If you had a third access pattern where you wanted to find all the actors in a particular movie, a local secondary index wouldn’t work. In this secondary index, you’d need to make Movie your partition key and Actor your sort key.
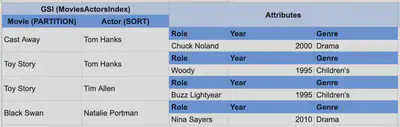
Difference between LSI and GSI
Local Secondary Index
- Index is local to a partition key
- Allows you to query items with the same partition key – specified with the query. All the items with a particular partition key in the table and the items in the corresponding local secondary index (together known as an item collection) are stored on the same partition. The total size of an item collection cannot exceed 10 GB.
- The partition key is the same as the table’s partition key. The sort key can be any scalar attribute.
- Can only be created when a table is created and cannot be deleted.
- Supports eventual consistency and strong consistency.
- Does not have its own provisioned throughput, instead they reuse the provisioned throughput from your base table
- Projected attributes are attributes stored in the index, and can be returned by queries and scans performed on the index. Local secondary index queries can also return attributes that are not projected by fetching them from the table
- Uses the WCU and RCU of the main table, no special throttling considerations
Global Secondary Index
- Index is across all partition keys
- Allows you to query over the entire table, across all partitions
- Can have a partition key and optional sort key that are different from the partition key and sort key of the original table.
- Key values do not need to be unique.
- Can be created when a table is created or can be added to an existing table and it can be deleted.
- Supports eventual consistency only.
- Has its own provisioned throughput settings for read and write operations.
- Global secondary index queries can only return projected attributes.
- If the writes are throttled on the GSI, then the main table will be throttled! even if the WCU on the main tables are fine. Choose your GSI partition key carefully! Assign your WCU capacity carefully!
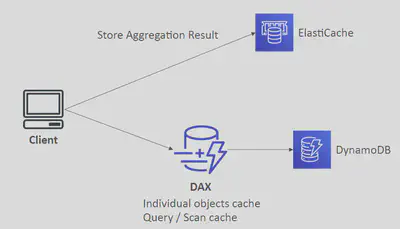
DynamoDB Accelerator(DAX)

- DynamoDB Accelerator or DAX is a fully managed, clustered in-memory cache for DynamoDB.
- Deliver up to 10x times read performance improvement.
- Gives you micro-second read performance for millions of requests per second. So it’s ideal for read heavy and also bursty read workloads for example auction applications, gaming applications and retail sites specifically during Black Friday promotions etc.
- DAX is right through caching service and this means that data is written to the cache as well as the back backend data store at the same time.
- You point your application to the DAX cluster instead of your DB.
- If the item you’re looking for is in the cache (cache hit) DAX will then return the result to the application however if the item is not available (cache miss) then DAX performs an eventually consistent get-item operation against DynamoDB and saves it in the cache and return it to the application.
- Not suitable for write intensive applications or applications that require strongly consistent reads. Solves the Hot Key problem (too many reads)
- 5 minutes TTL for cache by default
- Up to 10 nodes in the cluster
- Multi AZ (3 nodes minimum recommended for production)
- Secure (Encryption at rest with KMS, VPC, IAM,CloudTrail…)
Elasticache
It’s an in-memory cache in the cloud.
Improves performance of web applications allowing you to retrieve information from fast in memory cache rather than slower disk based databases.
Sits between your application and the database.
Takes the load of your databases and it’s really good if your application is particularly read heavy and also if the data is not changing very frequently.
2 types of Elasticache is available:
Memcached:
- Widely adopted memory object caching system.
- Multithreaded
- No Multi-AZ capability
Redis:
- Open-Source in-memory key-value store
- Supports more complex data structures like sorted sets and lists.
- Support Master/Slave replication and Multi-AZ for cross AZ redundancy.
Also there are 2 different caching strategies with Elasticache:
- Lazy Loading - Only caches the data when it’s requested. Data can become stale, and we can configure a TTL to overcome this problem
- Write Through - Data is written to the cache as well as the back backend data store at the same time. Data in the cache is never stale.
DAX vs ElastiCache
DynamoDB Transactions
- ACID Transactions (Atomic, Consistent, Isolated, Durable)
- Read or Write multiple items across multiple tables as an all or nothing operation.
- Check for a pre-requisite condition before writing to a table.
- Write Modes: Standard, Transactional
- Read Modes: Eventual Consistency, Strong Consistency, Transactional
- Consume 2x of WCU / RCU
- A transaction is a write to both table, or none!
DynamoDB TTL
If items in your table lose relevance with time, you can expire the old items to keep your storage cost low and your RCU consumption efficient. Rather than paying for the WCU required to delete the items you can have DynamoDB take care of it for you for free using the time-to-live (or TTL) feature. You can configure a particular attribute name as your expiry flag – any item which has that attribute is eligible for expiry. The attribute should contain a number representing the time after which deletion is allowed – this time should be in epoch format. Within a day or two of passing that expiry time, DynamoDB will delete the item for you – no WCUs are consumed. It’s going to be deleted within the next 48 hours.
- Good for removing any irrelevant or old data, so data that’s no longer useful to your application - Session data, Event logs etc. after a certain period of time and this is going to really help to reduce costs for storing data from DynamoDB because it automatically removes data which you no longer need.
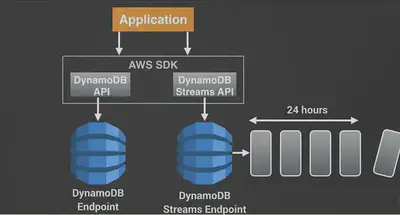
DynamoDB Streams
A DynamoDB Stream is an ordered flow of information about changes to a table. The records in the stream are strictly in the order in which the changes occurred. Each change contains exactly one stream record. A stream record is available for 24 hours. It records all of these actions as a log and the logs are encrypted at rest and they’re stored for 24 hours only
They’re mainly used to trigger events based on a particular change within the DynamoDB table. So they’re really good for serverless architectures.
There’s one end point to access the DynamoDB table itself and then there’s a second separate endpoint for the DynamoDB Stream.
This stream can be read by AWS Lambda & EC2 instances, and we can then do thing like:
- React to changes in real time (welcome email to new users)
- Analytics
- Create derivative tables / views
- Insert into ElasticSearch
Could implement cross region replication using Streams
Global Tables
Amazon DynamoDB global tables provide a fully managed solution for deploying a multi-region, multi-master database, without having to build and maintain your own replication solution. When you create a global table, you specify the AWS regions where you want the table to be available. DynamoDB performs all of the necessary tasks to create identical tables in these regions, and propagate ongoing data changes to all of them.
Backup and Restore
Your tables can easily be backed up and restored with DynamoDB.
Two types of backups are available –
- on-demand (takes a backup whenever you request it) and
- point-in-time recovery (or PITR).
PITR keeps a 35-day rolling window of information about your table – you can recover to any second within that 35 days. On-demand backups are almost instant, and neither type of backup consumes any capacity from your table.
Restore is made to a new table (or you can delete the original table first). Typically customers will want to restore to a separate table where they can look at the data to compare it with the current items – perhaps using this to selectively repair unintended changes which have been made in the table.
Alternatively, you can reconfigure clients to access a different table name.
Restore times vary by partition density, but most restores will complete in well under 10hrs.
This time does not scale linearly with your total table size – partitioned data is restored in parallel. For most production tables, PITR is a smart choice – and you can supplement this with on-demand backups for longer-term storage.
Design Considerations
Build Resilient Client Behavior:
Handle 400 and 500 Error Codes Gracefully
Handle 400 and 500 Error Codes Gracefully
Handle 400 and 500 error codes gracefully to ensure a smooth customer experience. For some 400 errors, you should fix the issue before re-submitting the request. For example:
- There was a problem with the request.
- Some required parameters were missing.
For other 400 errors, you can retry until the request succeeds. For example:
- Provisioned throughput was exceeded.
You can retry 500 errors until the request succeeds. For example
- An internal server error occurred.
- The service was unavailable.
Tune Retries
AWS SDKs have built-in retry logic, with reasonable defaults.
Tune for your use case to minimize visibility and hasten recovery for:
- Limits on retry attempts
- Timeouts
- Exponential back-off and jitter
Handle Errors in Batch Operations
Handle Errors in Batch Operations: Think of BatchGetItem and BatchWriteItem as simple wrappers around GetItem and PutItem/DeleteItem. Use returned information about unprocessed items (BatchGetItem: UnprocessedKeys, BatchWriteItem: UnprocessedItems) in the batch to create your own retry logic - be sure to implement exponential back-off in your application.
Batch operations can read or write items from one or more tables and individual requests in a batch operation may fail. The most likely reason for failure is that the table in question does not have enough provisioned read or write capacity. Use the information about failed tables and items to retry the batch operation with exponential backoff.